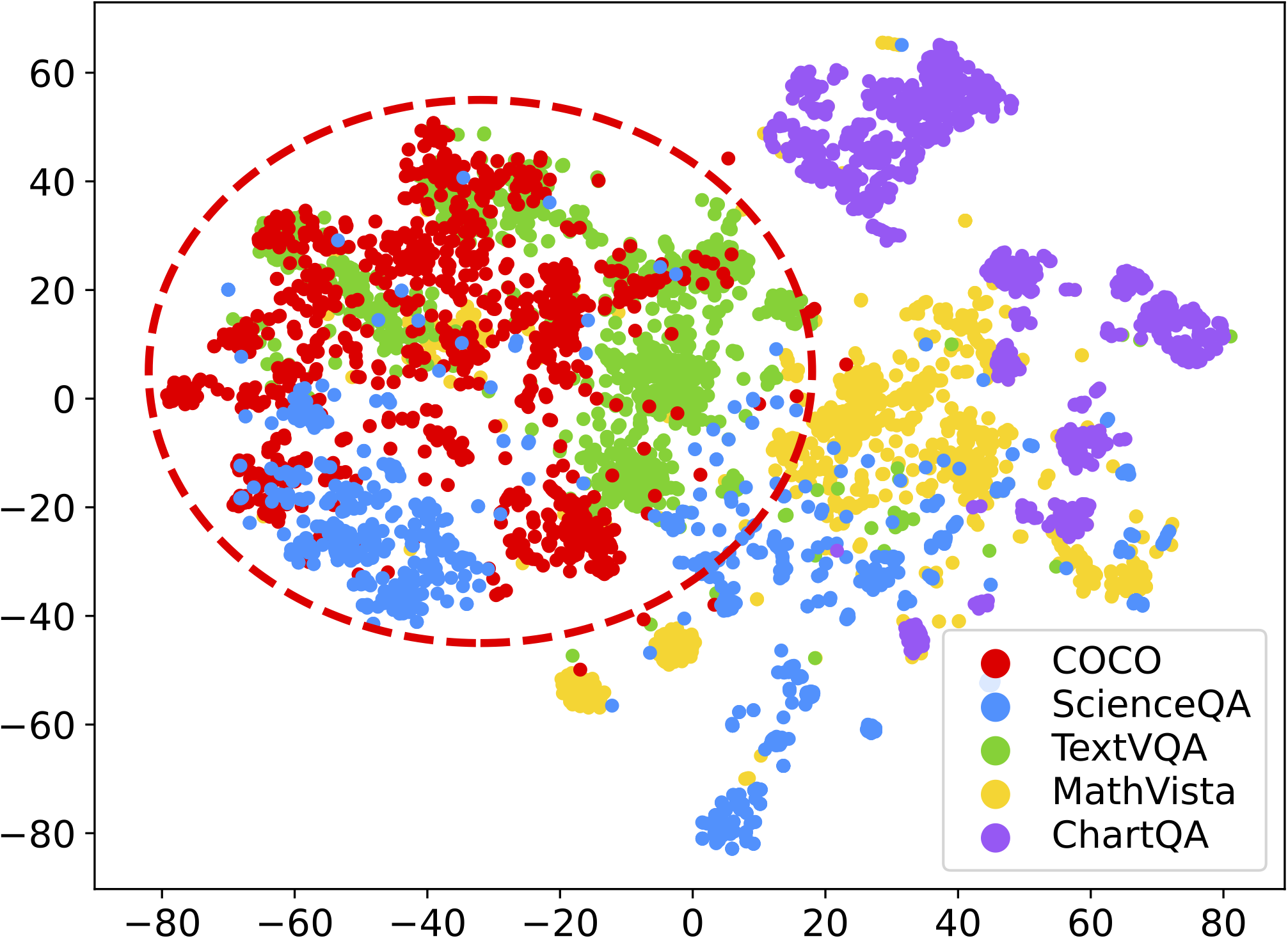
Large vision language models (LVLMs) integrate large language models (LLMs) with pre-trained vision encoders, thereby activating the perception capability of the model to understand image inputs for different queries and conduct subsequent reasoning. Improving this capability requires high-quality vision-language data, which is costly and labor-intensive to acquire. Self-training approaches have been effective in single-modal settings to alleviate the need for labeled data by leveraging model's own generation. However, effective self-training remains a challenge regarding the unique visual perception and reasoning capability of LVLMs.
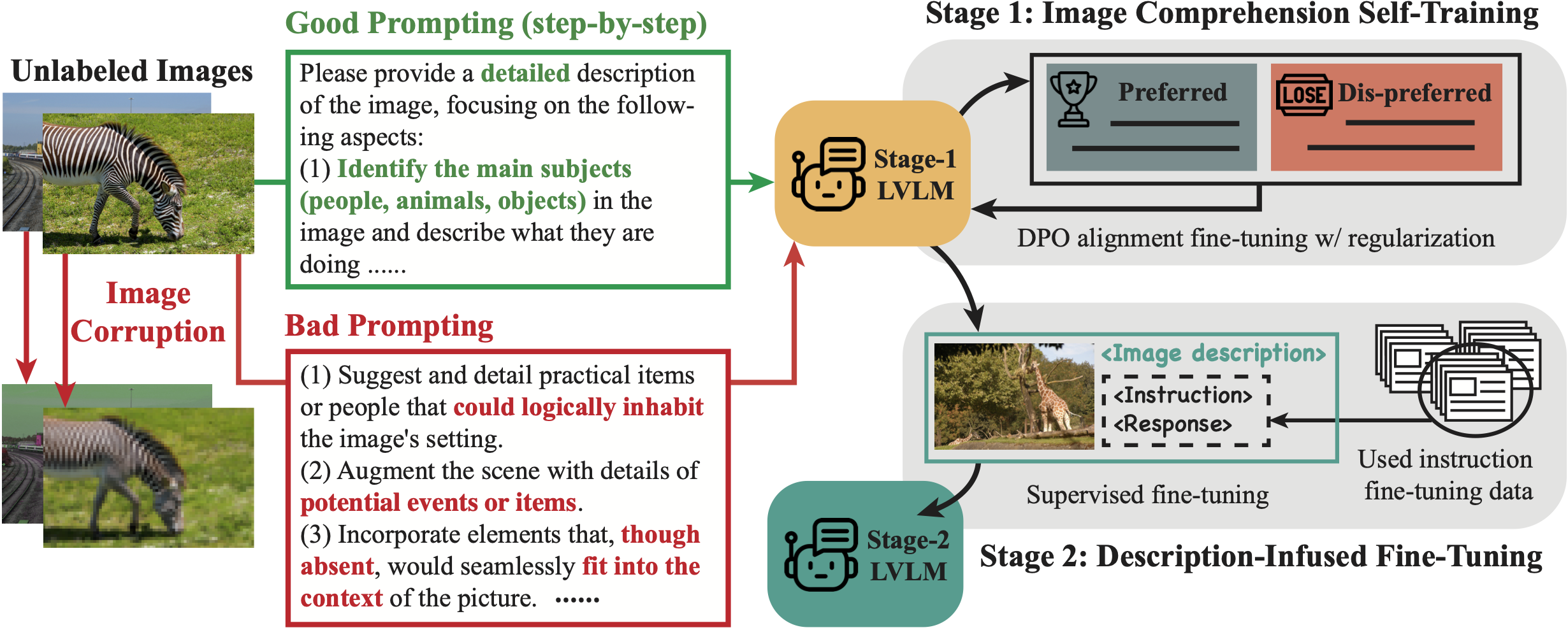
To address this, we introduce Self-Training on Image Comprehension (STIC), which emphasizes a self-training approach specifically for image comprehension. First, the model self-constructs a preference dataset for image descriptions using unlabeled images. Preferred responses are generated through a step-by-step prompt, while dis-preferred responses are generated from either corrupted images or misleading prompts. To further self-improve reasoning on the extracted visual information, we let the model reuse a small portion of existing instruction-tuning data and append its self-generated image descriptions to the prompts.
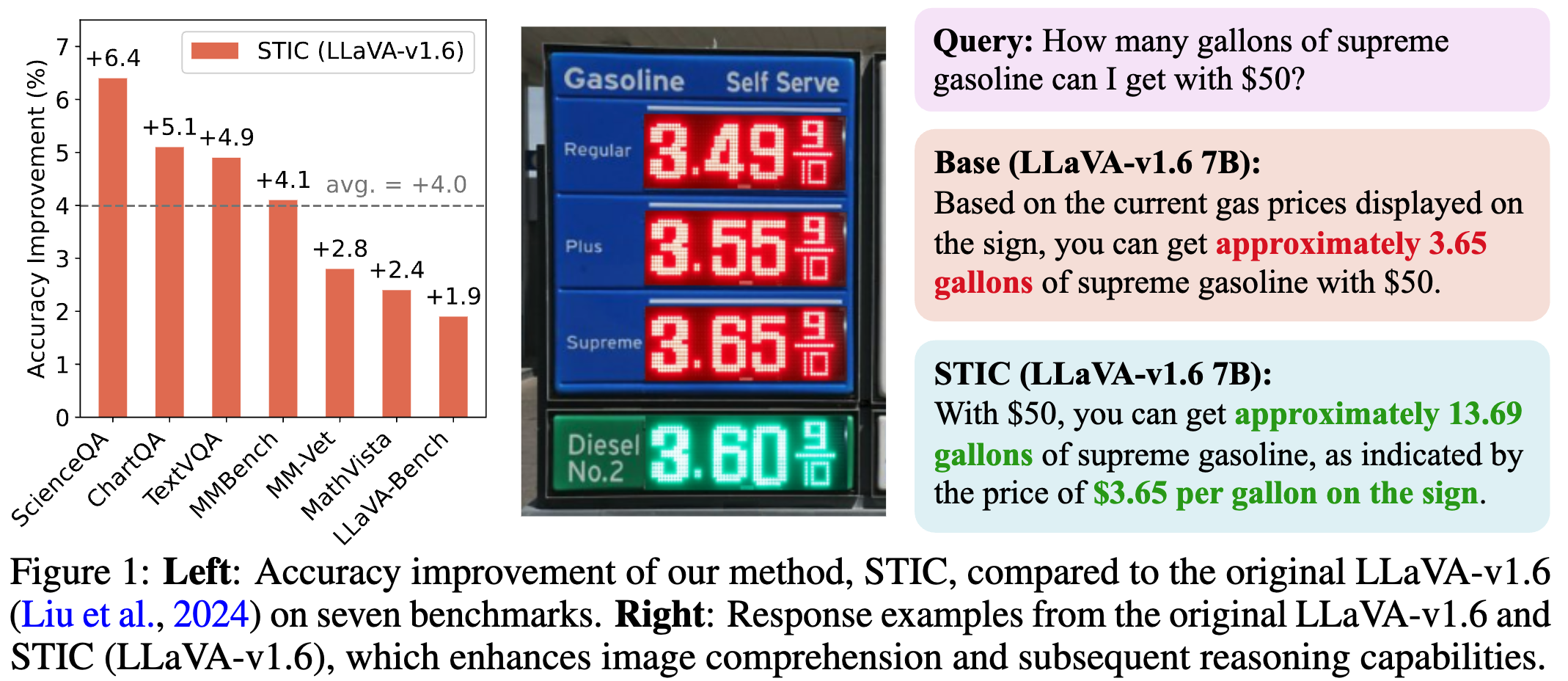
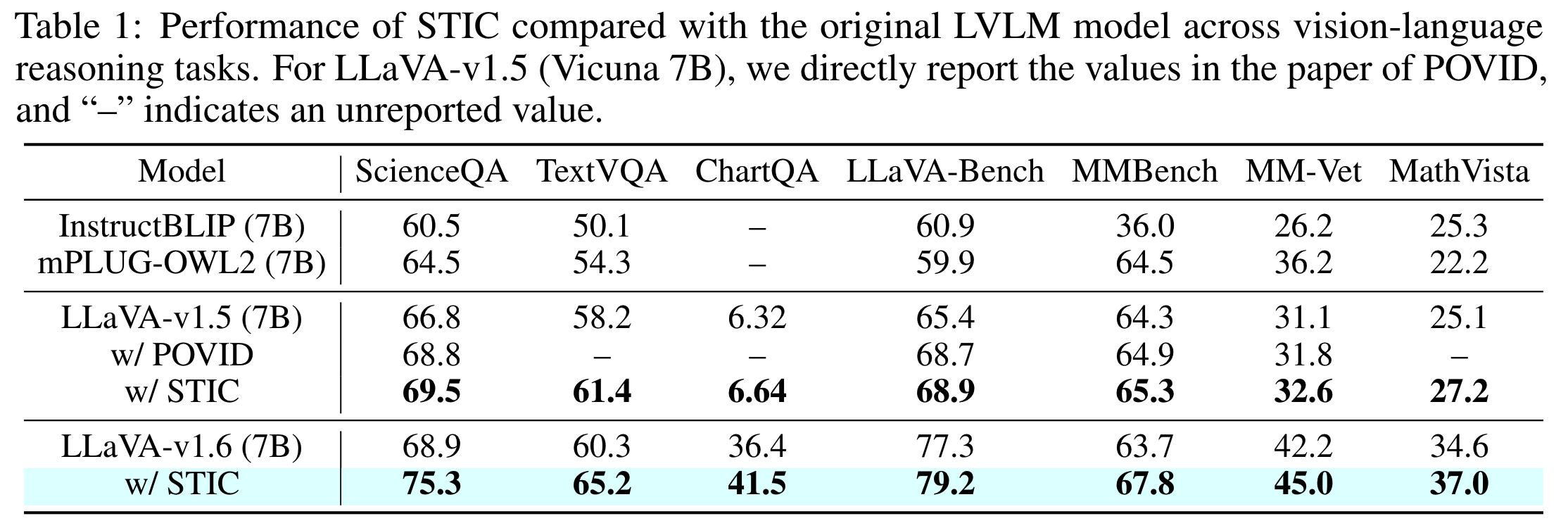
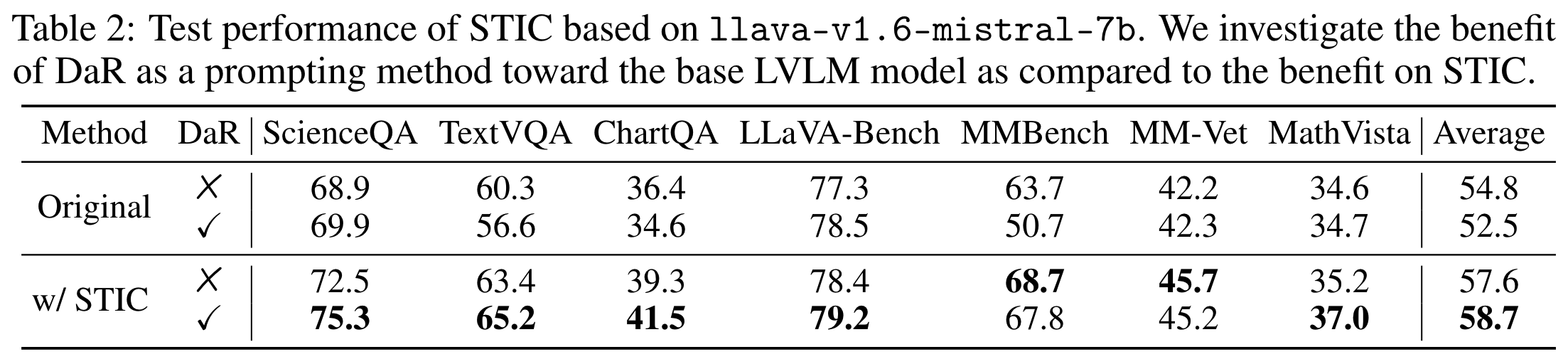
We validate the effectiveness of STIC across seven different benchmarks, demonstrating substantial performance gains of 4.0% on average while using 70% less supervised fine-tuning data than the current method. Further studies dive into various components of STIC and highlight its potential to leverage vast quantities of unlabeled images for self-training.